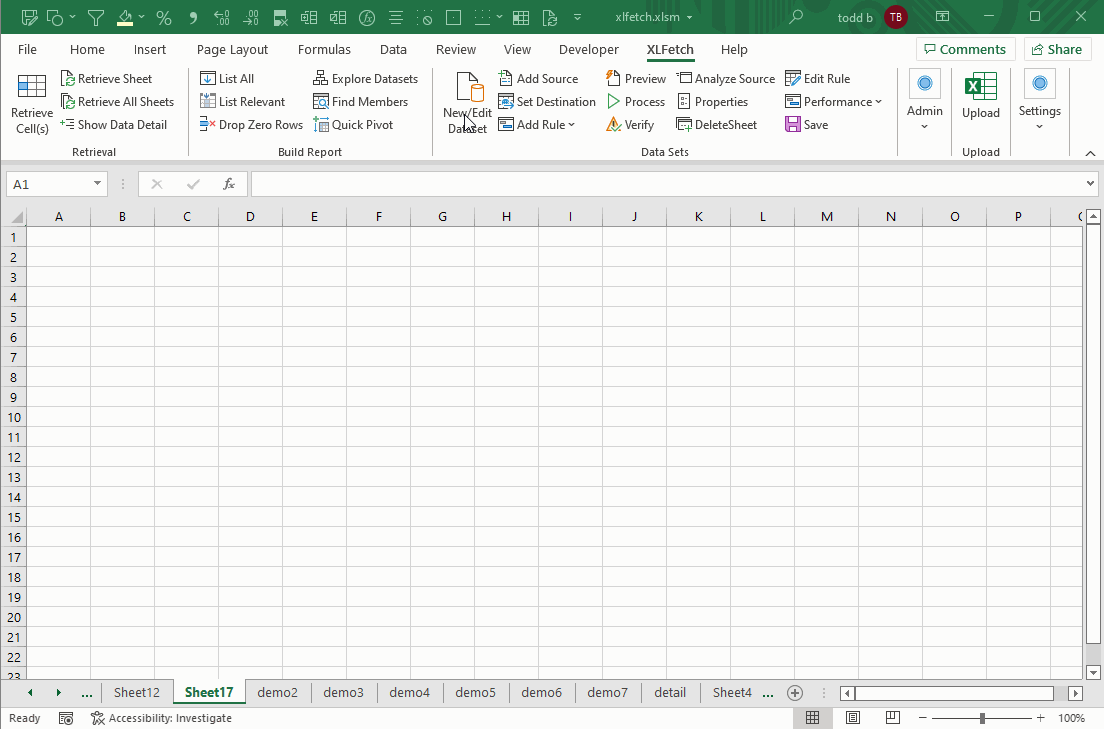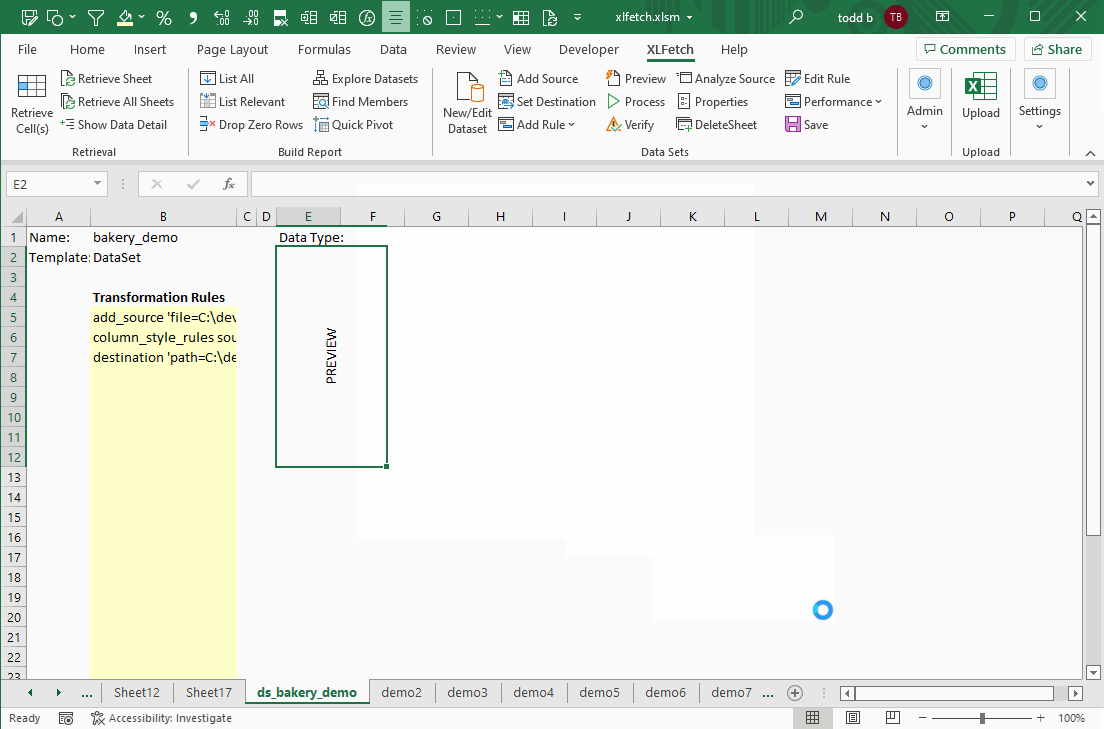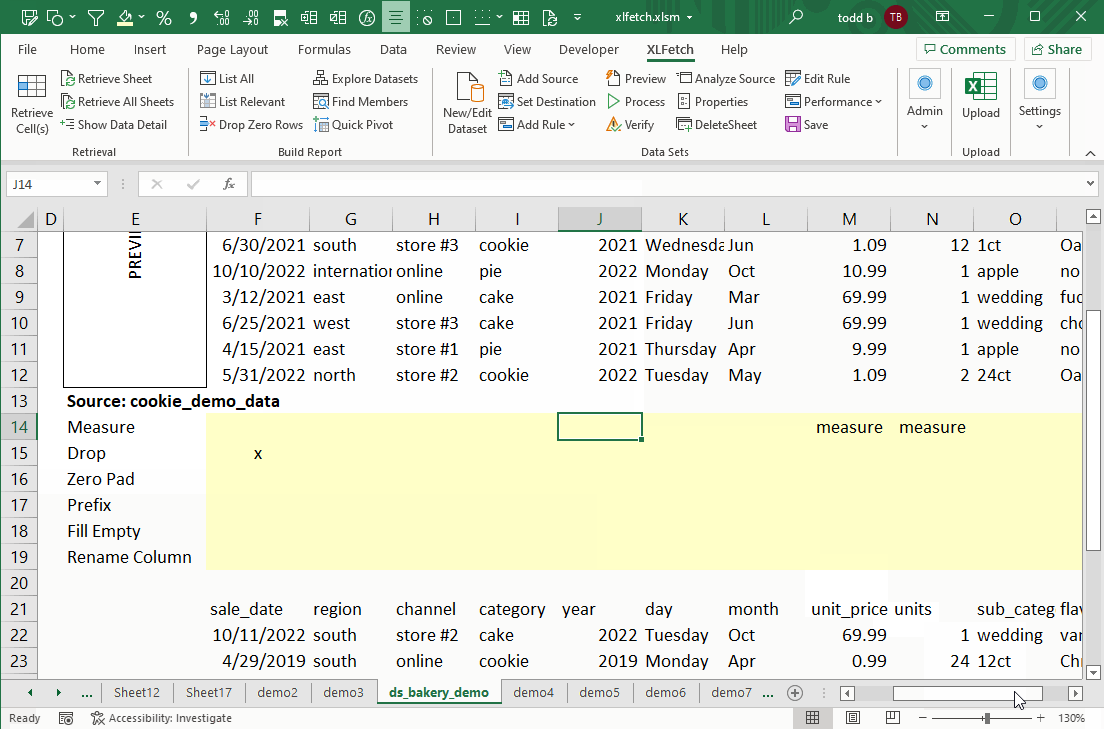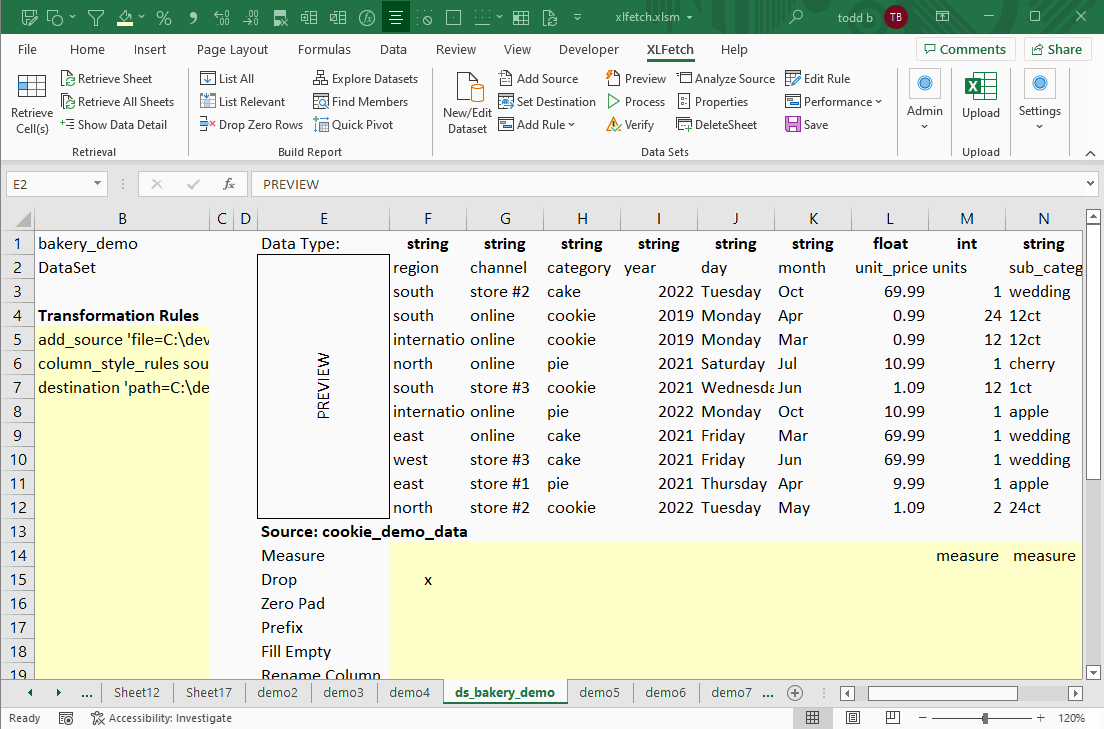
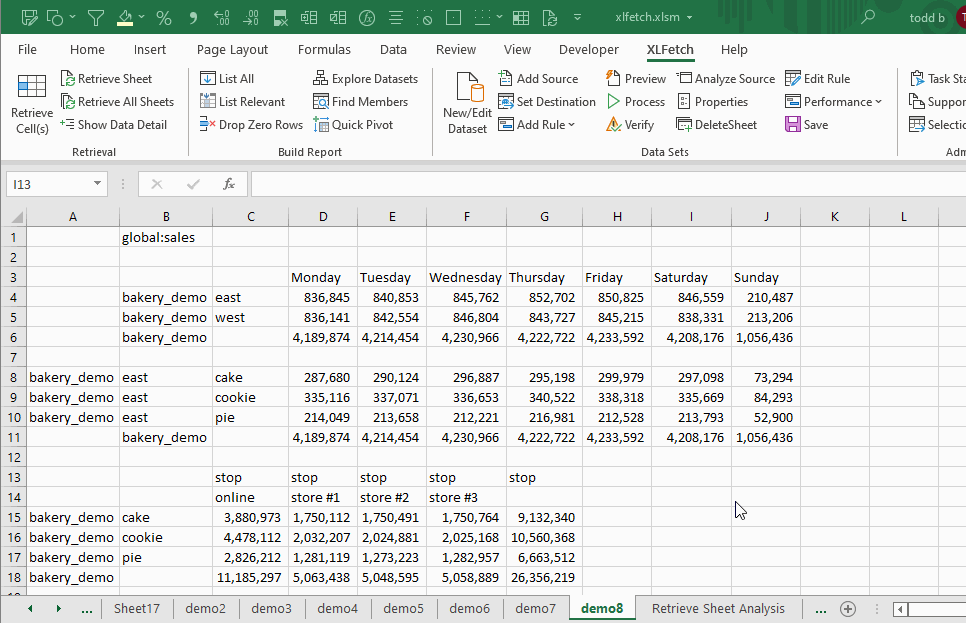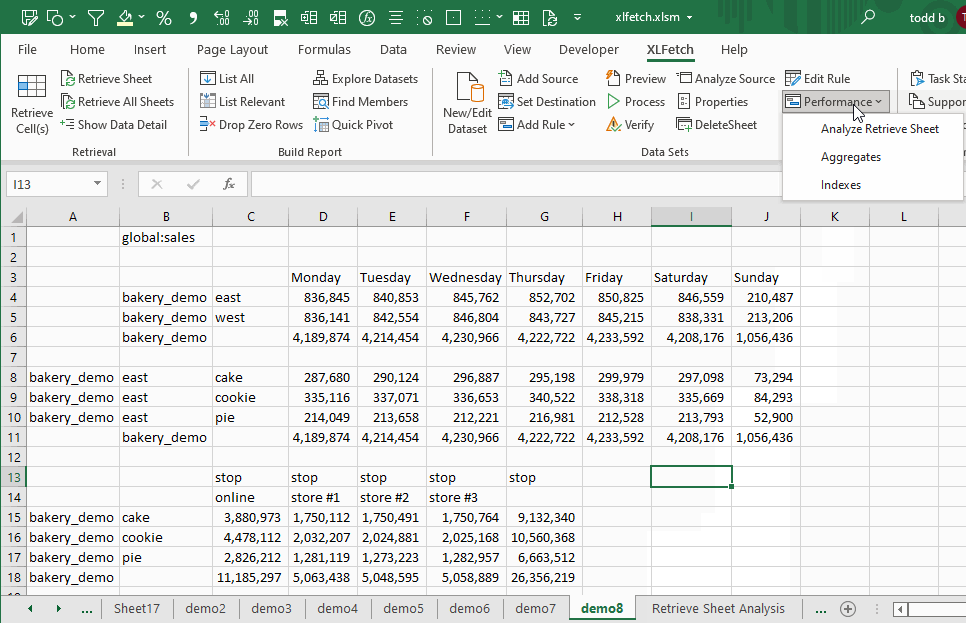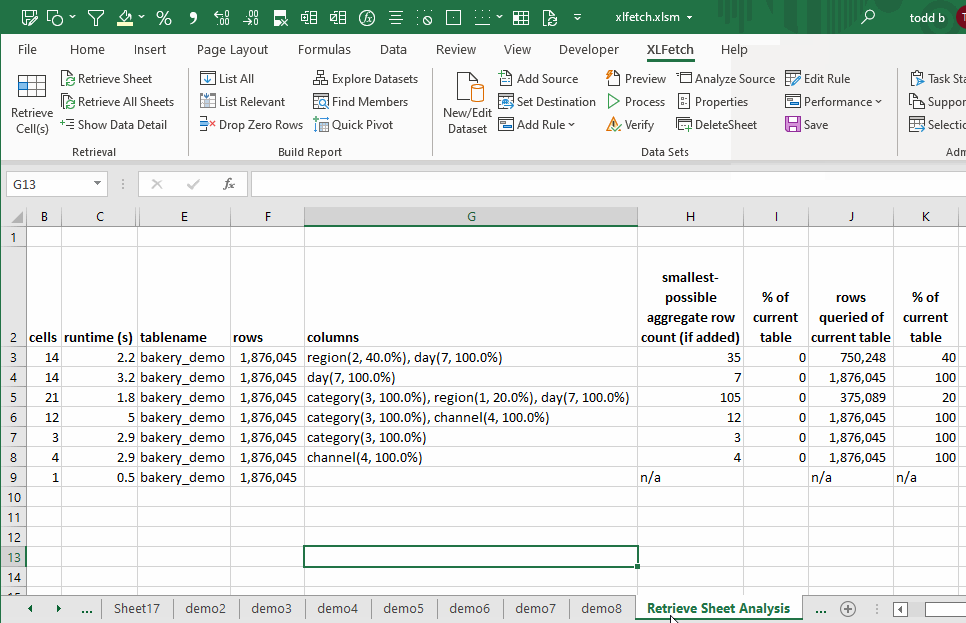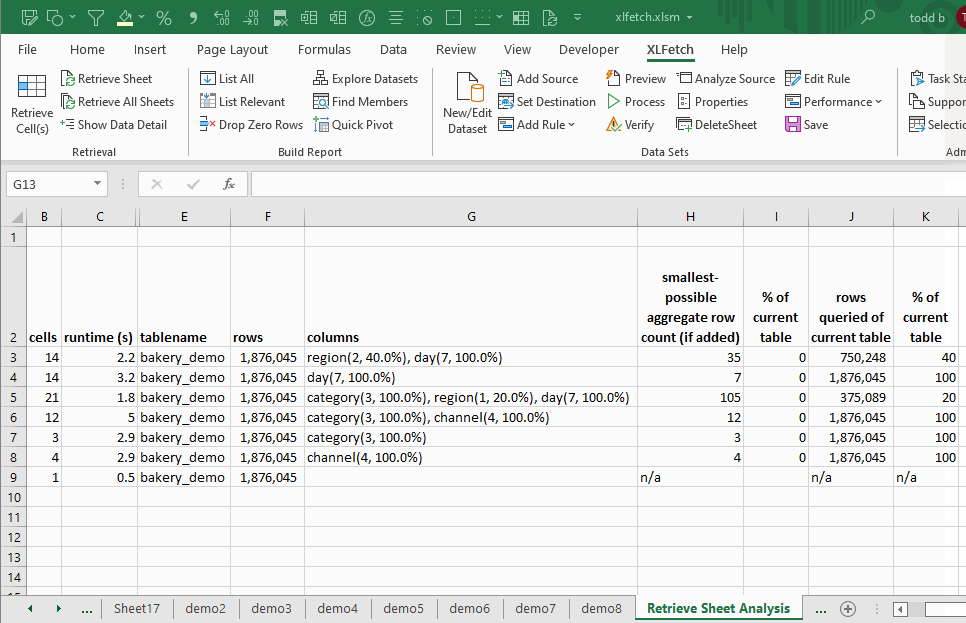
How Do I Create A Dataset?
1. Choose a data source.
2. Setup your destination.
XLFetch will show you a small preview of each data source, and provide a way clean your data with a few of the most frequently-used transformation rules.
3. Add one or more data transformation rules (optional). In most cases you'll want to make sure the values in your data are unique within each column.
4. Click 'Process' on the ribbon to process your data.